DOGZILLA-LITE机械狗
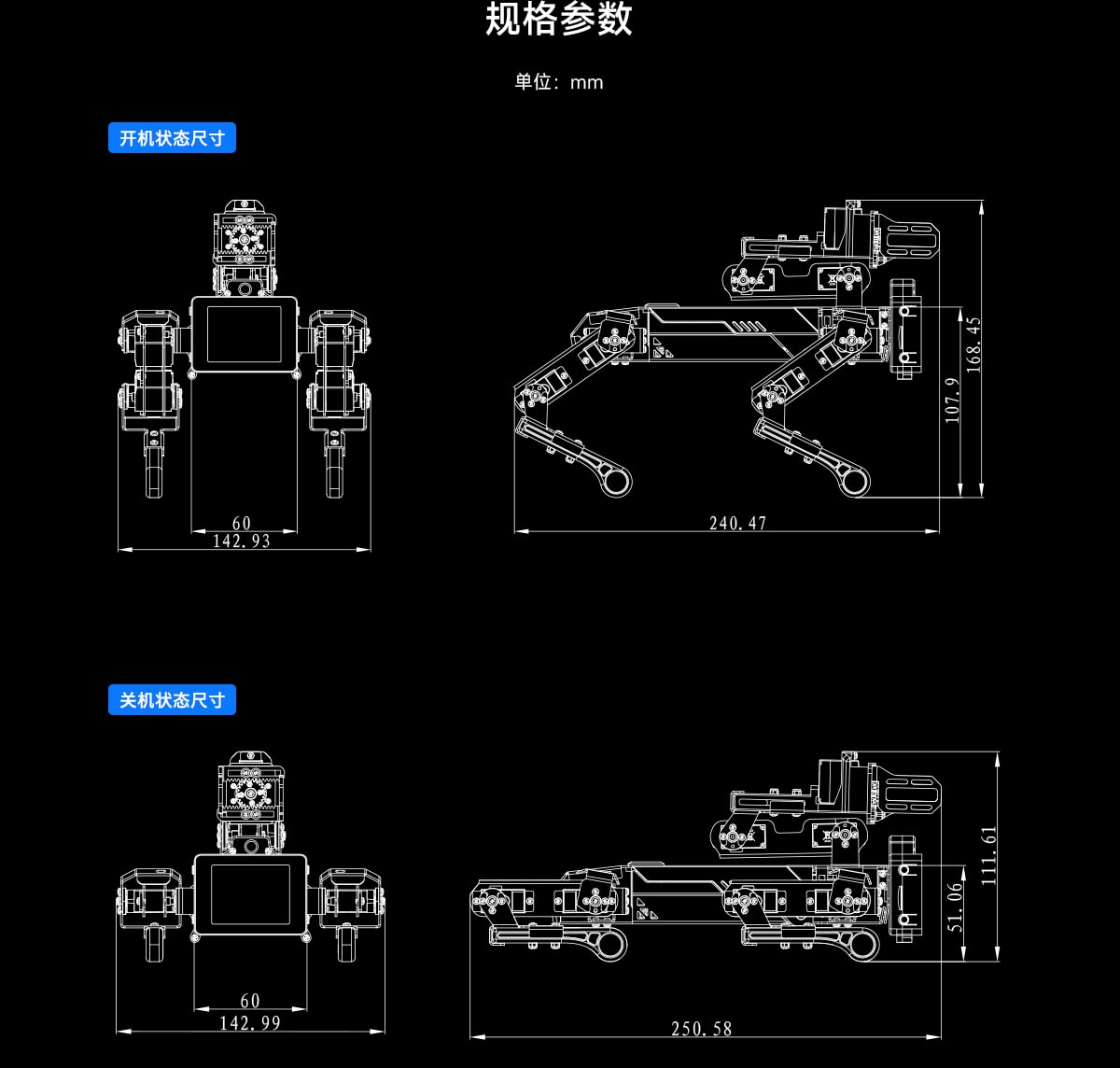
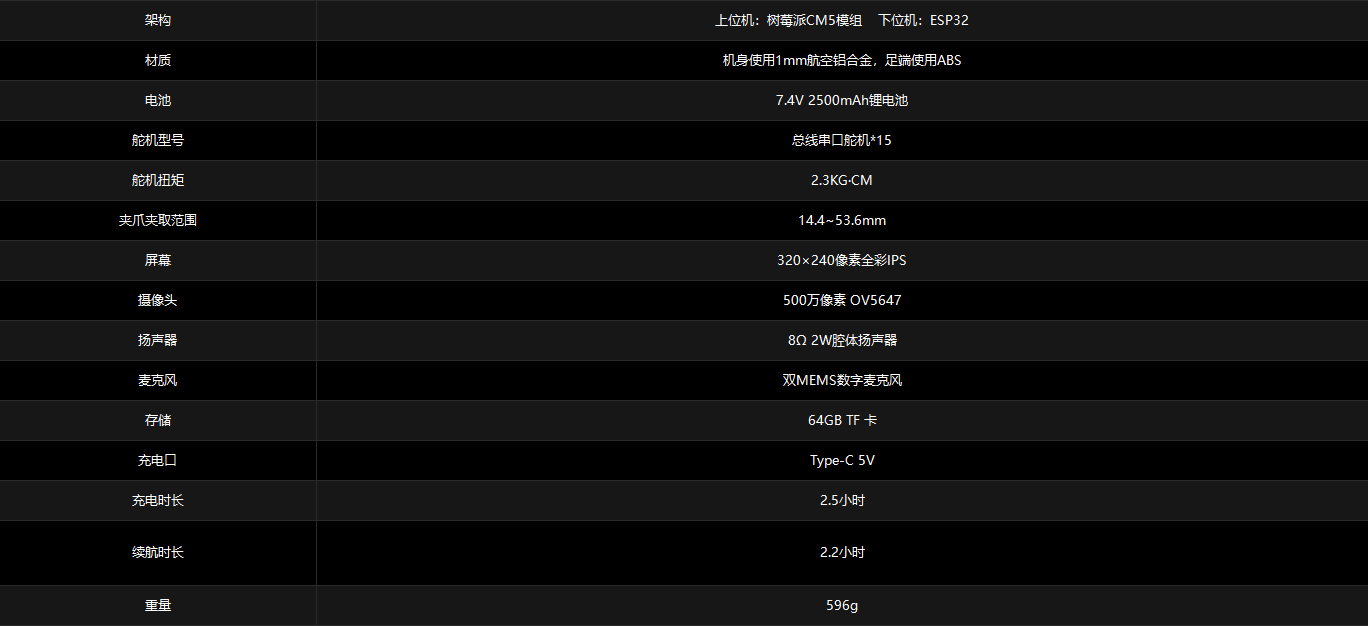
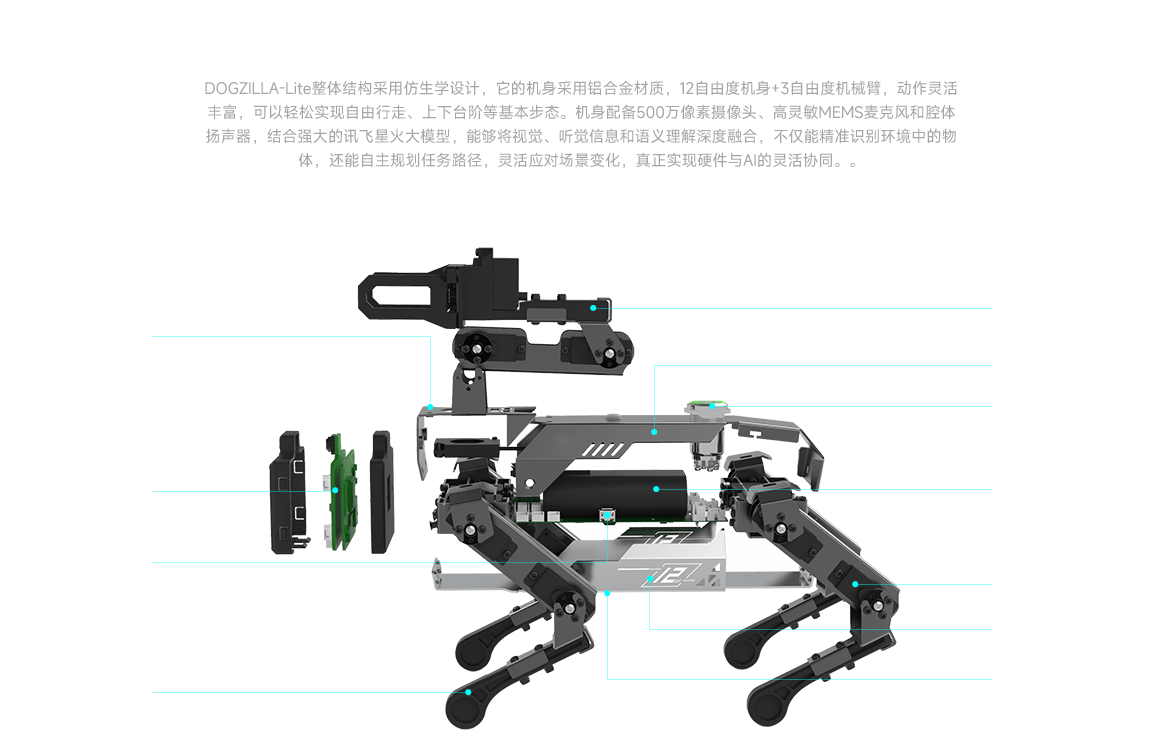
DOGZILLA-Lite 采用15个总线串口舵机,其中12个用于腿部关节,3个组成机械臂,单个舵机输出扭矩为2.3KG·CM,角度范围0-300°,并具备电流反馈功能,提供精准的运动控制与较高的操作稳定性。
DOGZILLA-Lite 背部搭载了3自由度机械臂,通过结合视觉识别,能够智能识别并精准抓取、搬运各类物品。未端夹爪具备电流保护反馈,可保护被抓取物品以及末端夹爪舵机。
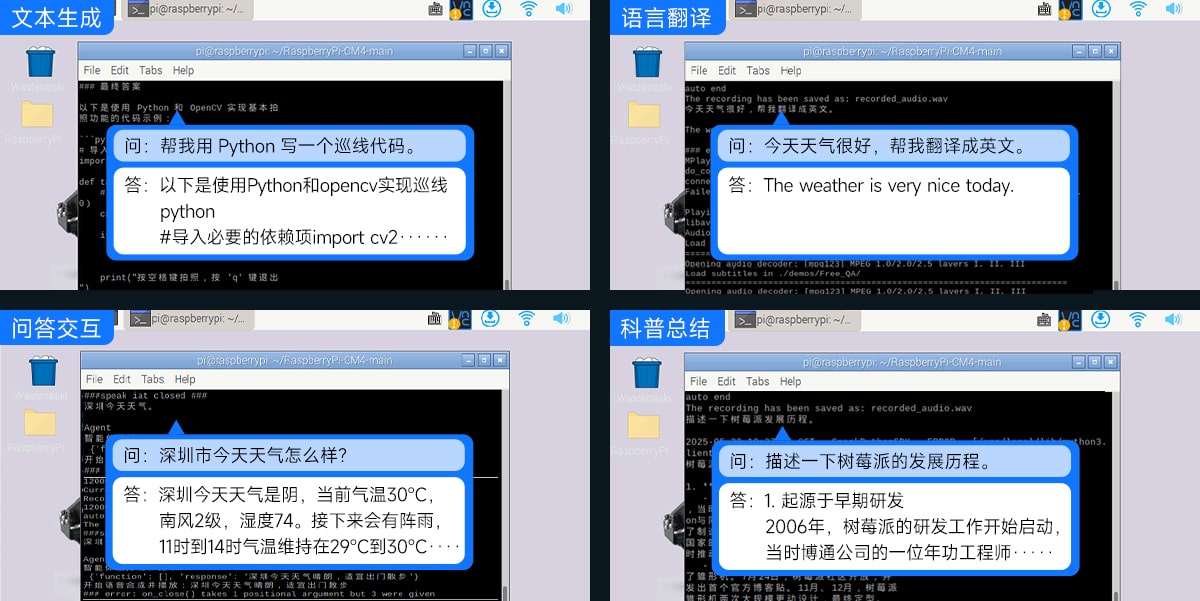
DOGZILLA-Lite 实时接入讯飞星火大模型,宛如配备“超级大脑”,不仅能理解文本指令,还能灵活应答。
DOGZILLA-Lite搭载高灵敏麦克风和扬声器,支持语音与文字实时互转,接入讯飞星火大模型后,能“听“会“说”,实现智能交互体验
DOGZILLA-Lite 配备 500万像素摄像头,能够理解和分析图像内容,精准识别物体,并输出文本和语音反馈。
DOGZILLA-Lite 支持语音自由对话可通过讯飞星火大模型识别语音输入内容,并进行答复。
支持调用讯飞星火大模型,识别用户语音输入内容,分析语义并执行相应的语音指令动作。
通过视觉大模型,DOGZILLA-Lite 能理解视野内的场景信息,并输出文本或语音反馈。
DOGZILLA-Lite 可以根据语音输入内容,自动生成一张相应的高质量图片。
通过大语言模型的语义理解,DOGZILLA-Lite 能根据指令锁定目标,实时调整机身姿态,精准完成追踪踢球动作。
通过大语言模型的语义理解,DOGZILLA-Lite 能够精准识别并实时追踪各种颜色的线条。
DOGZILLA-Lite 可以听到用户的指令,并通过大模型分析指令的含义,根据不同的指令,结合视觉识别内容做出不同的反馈进行回应。
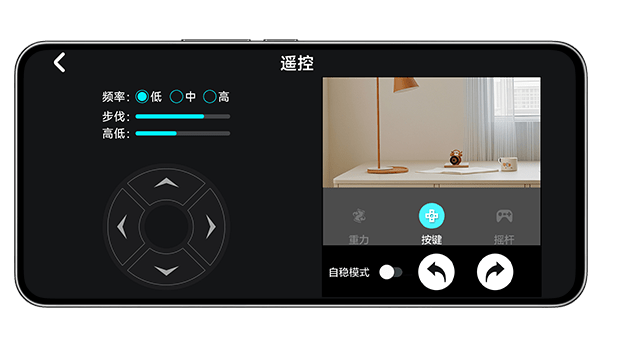
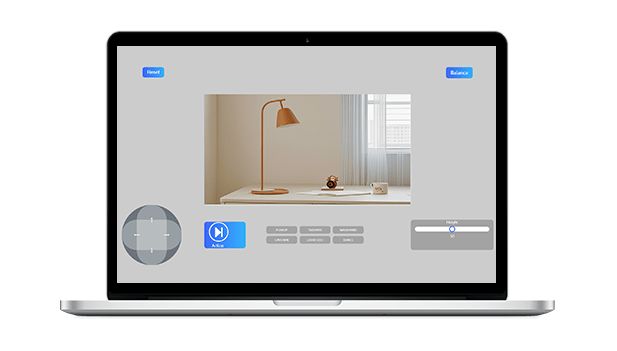
通过手机 APP,不仅可以控制 DOGZILLA-Lite 的自由运行,还能控制机械臂运动,进而完成抓取搬运的任务。
通过 AI视觉,DOGZILLA-Lite 能够识别指定物品,并对物品进行夹取和搬运。
通过 AI视觉,DOGZILLA-Lite 在自主巡线的过程中,可以识别路径上的障碍物利用机械臂可将障碍搬运移除。
通过大语言模型,用户能够通过语音指令控制 DOGZILLA-Lite 搬运对应物体放置到指定位置。
DOGZILLA-Lite 可以对杯子、椅子、鞋子、相机等三维物体进行检测框选。
DOGZILLA-Lite 可以检测人脸并且框选出来,同时显示检测的置信度。
DOGZILLA-Lite 支持识别车牌并在图像中显示识别结果。
DOGZILLA-Lite 支持对常见物体进行检测。
DOGZILLA-Lite 支持在画面中使用手指末端进行绘画。
DOGZILLA-Lite 支持检测面部表情识别生气、伤心和快乐等情绪。
DOGZILLA-Lite 可识别深蹲、俯卧撑、抬腿等多种运动姿态,实时统计运动数据。
DOGZILLA-Lite 通过识别手掌计算指尖距离,完成站起和蹲下动作
DOGZILLA-Lite 支持识别人体骨骼姿态,从而模仿人体完成站起和蹲下动作
DOGZILLA-Lite 可以追踪人脸,人脸位置变化,机器狗会随着动态调整位置。
DOGZILLA-Lite 可以追踪设定的目标颜色,跟随颜色执行向左转、向右转或前进动作。
DOGZILLA-Lite 识别二维码,执行二维码对应的前进、后退、向左、向右转动作。
DOGZILLA-Lite 可以给人脸带上虚拟面具,根据头部在图像的位置执行相应动作。
DOGZILLA-Lite 可以识别手势动作,手势往上,机器狗会站起,手势往下,机器狗会蹲下,手势往左右,机器狗也跟着往左右
DOGZILLA-Lite 可以识别 1/2/3/4/5/6/Good/OK/拳头等手势,并根据手势执行对应动作。
支持安卓/iOS手机APP控制
亚博智能配备精心研发的配套课程资料,提供基础理论知识与实操案例教程,内容由浅入深,方便用户快速上手学习。
搭配78课实操视频教程,视频包含程序启动、实操演示及实验现象,助力初学者快速体验机器狗的各项功能。
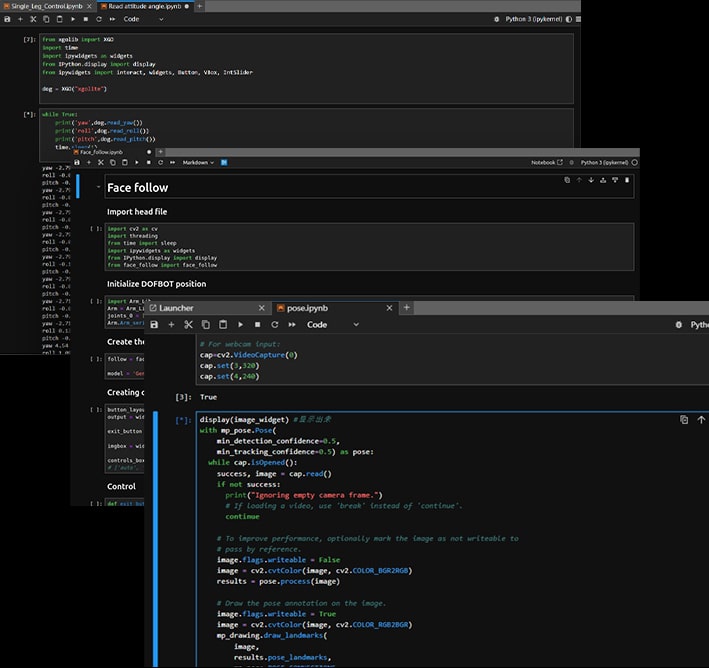
程序代码开源,让技术更自由,让创新更简单。





























-min.png)
-min.png)