AI大模型的理论概述
本章节只讲述多模太AI大模型相关的知识理论,没有兴趣的可以忽略本节。 本节不涉及机器狗的操作使用。
AI大模型的产生
1.多模态的定义与核心概念
多模态 (Multimodality): 指信息通过多种不同的“模态”或感官通道呈现和交互。
- 在AI领域,主要模态包括:
- 文本 (Text): 自然语言序列。
- 图像 (Image): 像素构成的视觉信息。
- 音频 (Audio): 声音波形或频谱,包含语音、音乐、环境音等。
- 视频 (Video): 图像序列与音频的组合,包含时空信息。
- 结构化数据 (Structured Data): 表格、知识图谱等。
- 大模型 (Large Models): 通常指基于Transformer架构、拥有巨大参数量(数十亿至数万亿) 和海量多源数据训练而成的基础模型 (Foundation Models)。它们具有强大的表示学习、上下文理解和迁移能力(如GPT系列、BERT系列、ViT系列等)。
- 多模态大模型 (Multimodal Large Models - MLLMs): 指能够同时处理、理解、关联和生成来自多种不同模态信息的大型人工智能模型。其核心目标是实现跨模态语义的统一表示、对齐与协同推理,模拟人类整合视觉、听觉、语言等感官信息进行认知的能力。
2. 技术架构演进
- 多模态大模型的核心在于整合文本、图像、音频、视频等多源数据,其架构经历了从单一模态到跨模态融合的转变:
- 早期单模态模型:如AlexNet(图像分类)、BERT(文本处理)等,仅针对单一任务设计,需独立训练不同模型。
- Transformer与大语言模型(LLM)的突破:通过统一框架(如GPT系列、CLIP)实现跨模态语义对齐,将不同数据映射到同一语义空间,减少信息损失。
- 端到端多模态建模:如GPT-4o、Google Gemini,通过单一模型直接处理多模态输入输出,消除中间转换步骤,提升效率。
- 关键组件与训练方法
- 编码器(Encoder):将不同模态数据(如图像像素、音频波形)转换为统一的高维特征向量,例如视觉编码器提取图像语义,文本编码器生成词嵌入。
- 跨模态注意力机制:动态调整各模态权重,例如微软BEiT-3通过跨模态注意力实现文本与图像的深度关联5。
- 预训练与微调:在大规模多模态数据(如LAION-5B)上进行预训练,再针对下游任务(如机器人控制、医疗诊断)微调,提升泛化能力。
- 跨模态对齐与知识融合
- 对齐技术:如CLIP通过对比学习对齐图像与文本特征,实现开放词表的零样本分类。
- 外部知识增强:模型如KOSMOS-1引入医学知识库,提升复杂问答的准确性。
3.多模态核心目标与意义
- 统一语义空间: 为不同模态的信息学习一个共享的、对齐的语义表示空间,使得同一概念在不同模态下的表示在向量空间中是相近的(如图片中的“猫”、文字“猫”、猫的叫声)。
- 跨模态理解: 基于一种模态的信息理解另一种模态的信息(例如:看图说话、听音辨图)。
- 跨模态生成: 利用一种模态的信息指导生成另一种模态的内容(例如:文生图、文生视频、图生文、语音合成带情感的语音)。
- 多模态协同推理: 综合利用多种模态的信息进行更复杂、更鲁棒、更接近人类认知的推理和决策(例如:基于视频和文字描述问答、结合医学影像和报告进行诊断)。
4. AI大模型应用层次
- 机器人及具身智能
- 通用化机器人:多模态LLM赋予机器人自主推理与学习能力,如特斯拉Optimus通过视觉、触觉等多传感器融合,适应非结构化环境。
- 实时交互与控制:谷歌RT-2模型将多模态输入直接转化为行动编码,在未知任务中成功率显著提升。
- 行业案例:波士顿动力Spot在博物馆担任导游,强调交互娱乐性而非纯功能性。
- 生成式内容创作
- 文生视频与3D建模:OpenAI Sora可生成高保真视频,Stable Diffusion 3支持3D内容生成,推动影视、游戏行业革新。
- 数字人与虚拟助手:如谷歌Project Astra、腾讯MM-LLMs,实现自然对话与实时视频剪辑。
3.垂直行业深度渗透
- 医疗诊断:数坤科技“数字人体”平台融合医学影像与病历文本,提升诊断效率5。
- 工业质检:多模态模型结合合成数据,检测复杂缺陷,错误率降低90%。
- 金融反欺诈:跨模态关联分析(如语音+交易记录)准确率达98%。
5.总结
- AI大模型多模态的核心理论在于构建能够统一理解、关联和生成异构模态信息的智能系统。它建立在深度学习(尤其是Transformer)、大规模自监督/弱监督预训练、对比学习、生成模型(自回归、扩散)等基础之上。通过解决模态异质性、对齐、融合等关键挑战,多模态大模型正在推动人工智能向更通用、更接近人类认知能力的方向发展,并在内容创作、人机交互、科学发现、教育医疗等领域展现出巨大潜力。
- 目前多模态大模型通过统一架构与跨模态融合,正在重构AI的能力边界,其应用从机器人到医疗、金融等领域展现出巨大潜力。
- 未来的研究将聚焦于效率、鲁棒性、动态理解、因果推理、具身智能以及伦理安全等重要方向,以实现“人机共生”的愿景。
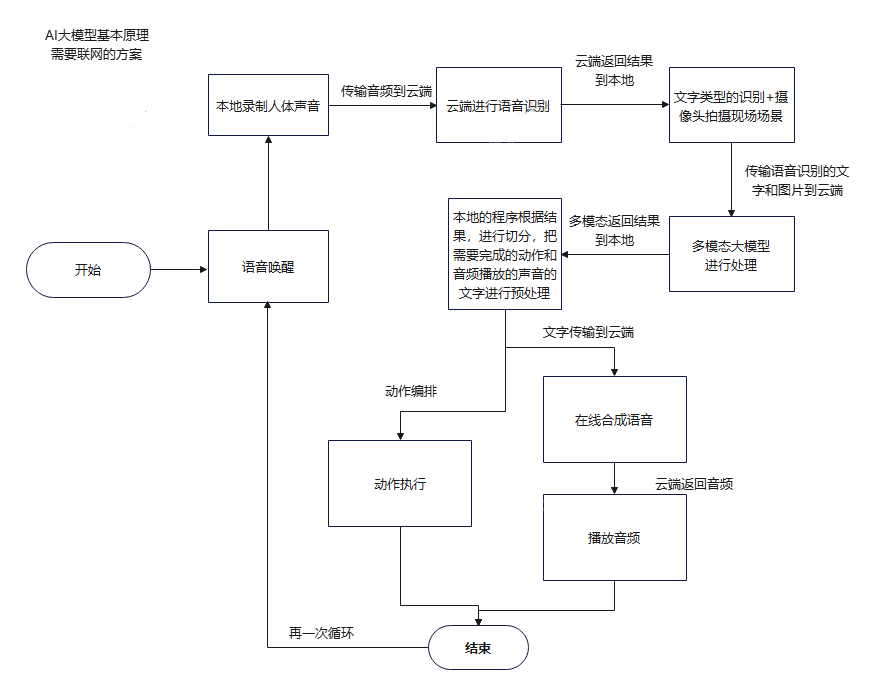
6.机器狗多模态的应用示例
机器狗的具身智能多模态结合在线平台方案如下: