训练对象检测模型
训练对象检测模型1.训练前的准备2.对基础模型进行下载3.进行图片素材的下载4.开始训练训练参数的配置说明5.将模型转换为ONNX6.导入要识别的图片如果想要打开摄像头进行识别可以输入以下命令7.识别结果
1.训练前的准备
在这个教程开始前,python必须安装好torchCPU+GPU版本,Yahboom的镜像是已经安装的了。如果没安装,请自行安装,需要科学上网,也可以看本系列教程的torch的安装教程。
cd jetson-inference/build./install-pytorch.sh因为基础模型已经有一些基础的信息,如果从头训练将会大大增加训练的时间,所以本教程只讲解对基础模型重新训练,如果想从头训练请看上一章的训练教程
2.对基础模型进行下载
xxxxxxxxxxcd /home/jetson/jetson-inference/python/training/detection/ssdwget https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O models/mobilenet-v1-ssd-mp-0_675.pthpip3 install -v -r requirements.txt
如果因为无法科学上网,导致模型下载不了,可以到/附录/模型文件下/fruit文件夹下找到,并把模型传到 /home/jetson/jetson-inference/python/training/detection/ssd/models文件下Yahboom的镜像则无需操作
3.进行图片素材的下载
xxxxxxxxxxcd /home/jetson/jetson-inference/python/training/detection/ssdpython3 open_images_downloader.py --class-names "Apple,Orange,Banana,Strawberry,Grape,Pear,Pineapple,Watermelon" --data=data/fruit
这条命令是把所有相关的图片都下载下来。 如果你的系统空间不足或者不想下这么多的图片可以使用一下的方法进行改进 YAHBOOM的镜像是把全部的相关的图片都下载了
xxxxxxxxxxpython3 open_images_downloader.py --stats-only --class-names "Apple,Orange,Banana,Strawberry,Grape,Pear,Pineapple,Watermelon" --data=data/fruit
在实践中,为了减少训练时间(和磁盘空间),您可能希望保持图像总数< 10K。虽然你用的图像越多,你的模型就越精确。您可以使用限制下载的数据量--max-images选项或--max-annotations-per-class选项:
- --stats-only:只下载对应类的图片,不会下载不必要的图片
- --max-images将总数据集限制为指定数量的图像,同时保持每个类的图像分布与原始数据集大致相同。如果一个类比另一个类有更多的图像,比例将大致保持不变。
- --max-annotations-per-class将每个类限制在指定数量的边界框内,如果一个类的可用边界框少于该数量,将使用它的所有数据——如果数据在类间的分布不平衡,这将非常有用。
例如,如果您只想对水果数据集使用2500张图像,您可以像这样启动下载程序:
xxxxxxxxxxpython3 open_images_downloader.py --max-images=2500 --class-names "Apple,Orange,Banana,Strawberry,Grape,Pear,Pineapple,Watermelon" --data=data/fruit
如果--max-boxes选项或--max-annotations-per-class未设置,默认情况下,所有可用的数据都将被下载——因此,在此之前,一定要先用--stats-only。
4.开始训练
xxxxxxxxxxcd /home/jetson/jetson-inference/python/training/detection/ssdpython3 train_ssd.py --data=data/fruit --model-dir=models/fruit --batch-size=4 --epochs=30
注意:如果内存不足或者您的流程在培训过程中被“终止”,请尝试安装交换和禁用桌面GUI.
xxxxxxxxxx#禁用桌面GUIsudo init 3 # stop the desktopsudo init 5 # restart the desktop
交换虚拟内存(参考链接):https://github.com/dusty-nv/jetson-inference/blob/master/docs/pytor ch-transfer-learning.md#mounting-swap
训练参数的配置说明
| 配置选项 | 默认值 | 描 述 |
|---|---|---|
| --data | data/ | 数据集的位置 |
| --model-dir | models/ | 输出已训练模型检查点的目录 |
| --resume | none | 要从中恢复训练的现有检查点的路径 |
| --batch-size | 4 | 根据可用内存尝试增加内存 |
| --epochs | 30 | 达到100是可取的,但会增加培训时间 |
| --workers | 2 | 数据加载器线程数(0 =禁用多线程) |
如果您想在全部纪元完成训练之前测试您的模型,您可以按Ctrl+C来终止训练脚本,并在以后使用--resume=
5.将模型转换为ONNX
接下来,我们需要将训练好的模型从PyTorch转换为ONNX,这样我们就可以用TensorRT加载它:
xxxxxxxxxxpython3 onnx_export.py --model-dir=models/fruit这将保存一个名为ssd-mobilenet.onnx下面的jetson-inference/python/training/detection/ssd/models/fruit/
6.导入要识别的图片
如果自己有相关的图片,可以把相关的图片上传到NX进行识别。没有可以到附录/模型文件/fruit下上传960张水果的图片到nx的/home/jetson/jetson-inference/python/training/detection/ssd/data上,即(images.zip)然后解压。
xxxxxxxxxxexport IMAGES=/home/jetson/jetson-inference/python/training/detection/ssd/data/imagescd $IMAGES && mkdir test && cd ../..detectnet --model=models/fruit/ssd-mobilenet.onnx --labels=models/fruit/labels.txt \--input-blob=input_0 --output-cvg=scores --output-bbox=boxes \"$IMAGES/fruit_*.jpg" $IMAGES/test/fruit_%i.jpg
输出的结果在 /home/jetson/jetson-inference/python/training/detection/ssd/data/test 文件路径下 如果使用的是自己的图片,想要运行上述命令,要把图片名改成fruit_*.jpg,图片必须是jpg格式的,否则自行更改运行命令,本教程不在阐述了
如果想要打开摄像头进行识别可以输入以下命令
xdetectnet --model=models/fruit/ssd-mobilenet.onnx --labels=models/fruit/labels.txt \--input-blob=input_0 --output-cvg=scores --output-bbox=boxes \csi://0 #csi摄像头detectnet --model=models/fruit/ssd-mobilenet.onnx --labels=models/fruit/labels.txt \--input-blob=input_0 --output-cvg=scores --output-bbox=boxes \v4l2:///dev/video0 #对v4l2摄像头
其它视频流文件的打开方式,可参考:https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md
7.识别结果
YAHBOOM的镜像中存在了用训练30次的模型和训练100次的模型的识别结果
30次的结果:/home/jetson/jetson-inference/python/training/detection/ssd/data/test_30
100次的结果:/home/jetson/jetson-inference/python/training/detection/ssd/data/test_100
本教程随机选取图片进行对比
结果的如图所示:
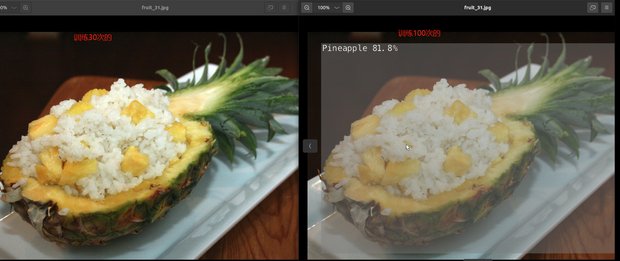
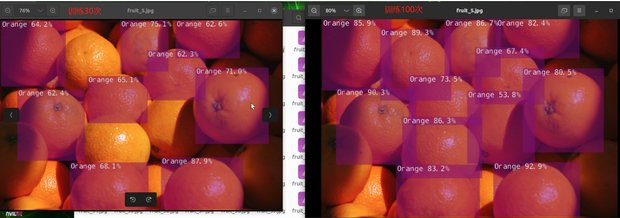 可见,训练次数越小,精度不高,很可能导致图像无法识别的原因出现。
可见,训练次数越小,精度不高,很可能导致图像无法识别的原因出现。