1、Opencv应用
1、Opencv应用1.1、概述1.2、QR二维码1.2.1、QR码的简介1.2.2、QR码的结构1.2.3、QR码的特点1.2.4、QR二维码创建与识别1.3、人体姿态估计1.3.1、概述1.3.2、原理1.3.3、启动1.4、目标检测1.4.1、模型结构1.4.2、代码解析1.4.3、启动
1.1、概述
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和MacOS操作系统上。 [1] 它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
1.2、QR二维码
1.2.1、QR码的简介
QR码是二维条码的一种,QR 来自英文 “Quick Response” 的缩写,即快速反应的意思,源自发明者希望 QR 码可让其内容快速被解码。QR码不仅信息容量大、可靠性高、成本低,还可表示汉字及图像等多种文字信息、其保密防伪性强而且使用非常方便。更重要的是QR码这项技术是开源的。
1.2.2、QR码的结构
| 图片 | 解析 |
|---|---|
 | 定位标识 (Positioning markings)标明二维码的方向。 |
 | 对齐标记(Alignment markings)如果二维码很大,这些附加元素帮助定位。 |
 | 计算模式(Timing pattern)通过这些线,扫描器可以识别矩阵有多大。 |
 | 版本信息(Version information)这里指定正在使用的QR码的版本号,目前有QR码有40个不同的版本号。 用于销售行业的的版本号通常为1-7。 |
 | 格式信息(Format information)格式模式包含关于容错和数据掩码模式的信息,并使得扫描代码更加容易。 |
 | 数据和错误校正值(Data and error correction keys)这些模式保存实际数据。 |
 | 宁静区域(Quiet zone)这个区域对于扫描器来说非常重要,它的作用就是将自身与周边的进行分离。 |
1.2.3、QR码的特点
QR码中数据值包含重复的信息(冗余值)。因此,即使多达30%的二维码结构被破坏,而不影响二维码的可读性。QR码的存储空间多达7089位或者是4296个字符,包括标点符号和特殊字符,都可以写入QR码中。除了数字和字符之外,还可以对单词和短语(例如网址)进行编码。随着更多的数据被添加到QR码,代码大小增加,代码结构变得更加复杂。
1.2.4、QR二维码创建与识别
源码路径:~/transbot_ws/src/transbot_visual/simple_qrcode
安装
python3 -m pip install qrcode pyzbarsudo apt-get install libzbar-dev
- 创建
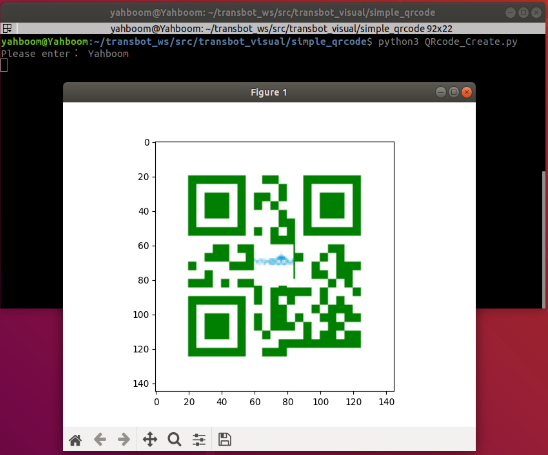
创建qrcode对象
xxxxxxxxxx ''' 参数含义: version:值为1~40的整数,控制二维码的大小(最小值是1,是个12×12的矩阵)。 如果想让程序自动确定,将值设置为 None 并使用 fit 参数即可。 error_correction:控制二维码的错误纠正功能。可取值下列4个常量。 ERROR_CORRECT_L:大约7%或更少的错误能被纠正。 ERROR_CORRECT_M(默认):大约15%或更少的错误能被纠正。 ROR_CORRECT_H:大约30%或更少的错误能被纠正。 box_size:控制二维码中每个小格子包含的像素数。 border:控制边框(二维码与图片边界的距离)包含的格子数(默认为4,是相关标准规定的最小值) ''' qr = qrcode.QRCode( version=1, error_correction=qrcode.constants.ERROR_CORRECT_H, box_size=5, border=4,)qrcode二维码添加logo
xxxxxxxxxx # 如果logo地址存在,就添加logo图片 my_file = Path(logo_path) if my_file.is_file(): img = add_logo(img, logo_path)注意:使用中文时,需加中文字符
xxxxxxxxxx直接使用python3 + py文件执行即可,然后输入要生成的内容,回车确认。
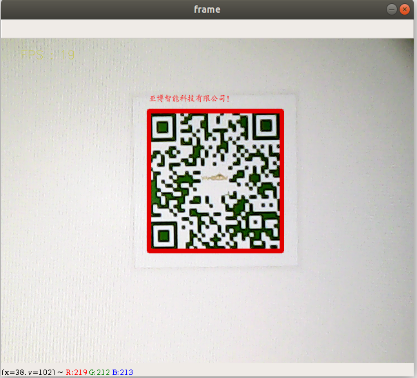
- 识别
xxxxxxxxxxdef decodeDisplay(image, font_path): gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY) # 需要先把输出的中文字符转换成Unicode编码形式 barcodes = pyzbar.decode(gray) for barcode in barcodes: # 提取二维码的边界框的位置 (x, y, w, h) = barcode.rect # 画出图像中条形码的边界框 cv.rectangle(image, (x, y), (x + w, y + h), (225, 0, 0), 5) encoding = 'UTF-8' # 画出来,就需要先将它转换成字符串 barcodeData = barcode.data.decode(encoding) barcodeType = barcode.type # 绘出图像上数据和类型 pilimg = Image.fromarray(image) # 创建画笔 draw = ImageDraw.Draw(pilimg) # 参数1:字体文件路径,参数2:字体大小 fontStyle = ImageFont.truetype(font_path, size=12, encoding=encoding) # 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体 draw.text((x, y - 25), str(barcode.data, encoding), fill=(255, 0, 0), font=fontStyle) # PIL图片转cv2 图片 image = cv.cvtColor(np.array(pilimg), cv.COLOR_RGB2BGR) # 向终端打印条形码数据和条形码类型 print("[INFO] Found {} barcode: {}".format(barcodeType, barcodeData)) return image- 效果演示
xxxxxxxxxx直接使用python3 + py文件执行即可
1.3、人体姿态估计
源码路径:~/transbot_ws/src/transbot_visual/detection
1.3.1、概述
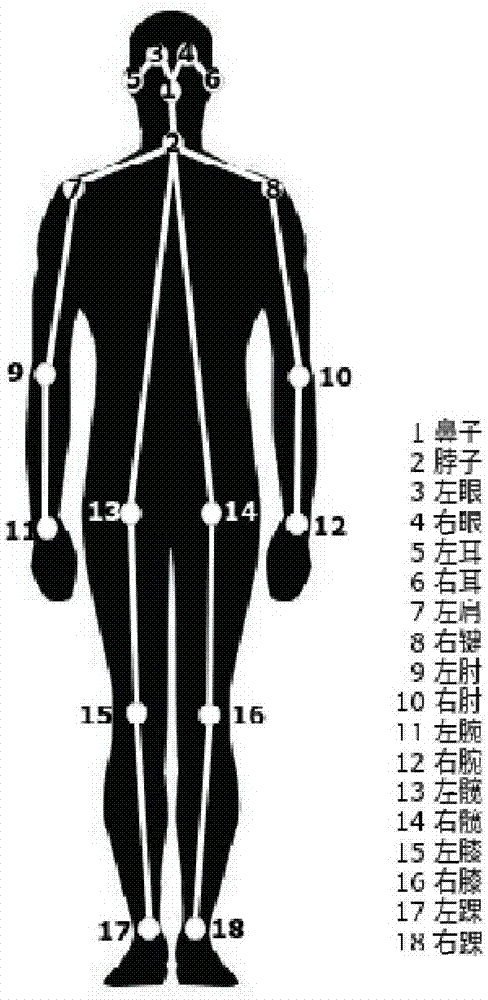
人体姿态估计(Human Posture Estimation),是通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。人体关键点通常对应人体上有一定自由度的关节,比如颈、肩、肘、腕、腰、膝、踝等,如下图。
1.3.2、原理
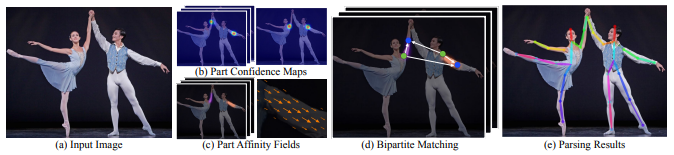
输入一幅图像,经过卷积网络提取特征,得到一组特征图,然后分成两个岔路,分别使用 CNN网络提取Part Confidence Maps 和 Part Affinity Fields; 得到这两个信息后,我们使用图论中的 Bipartite Matching(偶匹配) 求出Part Association,将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架; 最后基于PAFs求Multi-Person Parsing—>把Multi-person parsing问题转换成graphs问题—>Hungarian Algorithm(匈牙利算法) (匈牙利算法是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。)
1.3.3、启动
xxxxxxxxxxcd ~/transbot_ws/src/transbot_visual/detectionpython target_detection.py
点击图像框后,使用键盘【f】键切换目标检测。
xxxxxxxxxxif action == ord('f'):state = not state # 功能切换输入图片

输出图片

1.4、目标检测
本节主要解决的问题是如何使用OpenCV中的dnn模块,用来导入一个实现训练好的目标检测网络。但是对opencv的版本是有要求的。
目前用深度学习进行目标检测,主要有三种方法:
- Faster R-CNNs
- You Only Look Once(YOLO)
- Single Shot Detectors(SSDs)
Faster R-CNNs是最常听说的基于深度学习的神经网络了。然而,这种方法在技术上是很难懂的(尤其是对于深度学习新手),也难以实现,训练起来也是很困难。
此外,即使是使用了“Faster”的方法实现R-CNNs(这里R表示候选区域Region Proposal),算法依然是比较慢的,大约是7FPS。
如果我们追求速度,我们可以转向YOLO,因为它非常的快,在TianXGPU上可以达到40-90 FPS,最快的版本可能达到155 FPS。但YOLO的问题在于它的精度还有待提高。
SSDs最初是由谷歌开发的,可以说是以上两者之间的平衡。相对于Faster R-CNNs,它的算法更加直接。相对于YOLO,又更加准确。
1.4.1、模型结构
MobileNet的主要工作是用depthwise sparable convolutions(深度级可分离卷积)替代过去的standard convolutions(标准卷积)来解决卷积网络的计算效率和参数量的问题。MobileNets模型基于是depthwise sparable convolutions(深度级可分离卷积),它可以将标准卷积分解成一个深度卷积和一个点卷积(1 × 1卷积核)。深度卷积将每个卷积核应用到每一个通道,而1 × 1卷积用来组合通道卷积的输出。
在MobileNet的基本组件中会加入Batch Normalization(BN),即在每次SGD(随机梯度下降)时,标准化处理,使得结果(输出信号各个维度)的均值为0,方差为1。一般在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
除此之外,模型还使用ReLU激活函数,所以depthwise separable convolution的基本结构如下图所示:
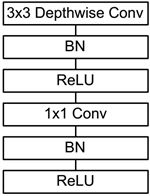
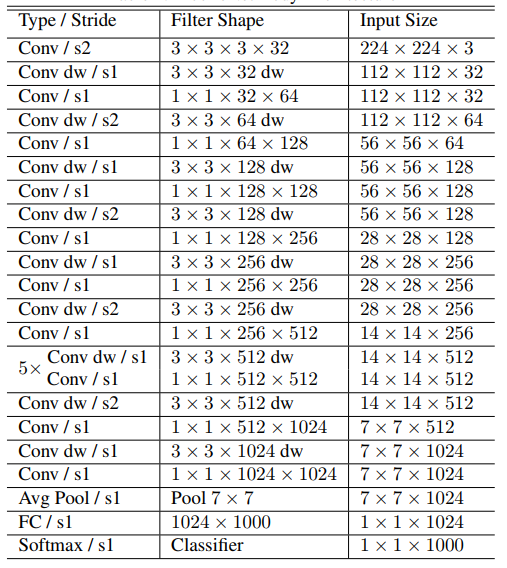
而MobileNets网络是由很多上图所示的depthwise separable convolution组合而成的。其具体的网络结构如下图所示:
1.4.2、代码解析
可识别的物体列表
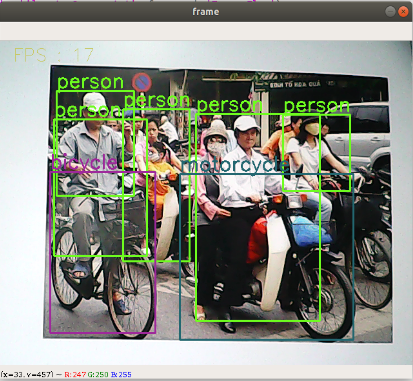
xxxxxxxxxx[person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, street sign, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, hat, backpack, umbrella, shoe, eye glasses, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, plate, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, mirror, dining table, window, desk, toilet, door, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, blender, book, clock, vase, scissors, teddy bear, hair drier, toothbrush]加载类别【object_detection_coco.txt】,导入模型【frozen_inference_graph.pb】,指定深度学习框架【TensorFlow】
xxxxxxxxxx# 加载COCO类名称with open('object_detection_coco.txt', 'r') as f: class_names = f.read().split('\n')# 对于不同目标显示不同颜色COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))# 加载DNN图像模型model = cv.dnn.readNet(model='frozen_inference_graph.pb', config='ssd_mobilenet_v2_coco.txt', framework='TensorFlow')导入图片,提取了高度和宽度,计算了300x300的像素blob,把这个blob传入神经网络
xxxxxxxxxxdef Target_Detection(image): image_height, image_width, _ = image.shape # 从图像中创建blob blob = cv.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True) model.setInput(blob) output = model.forward() # 遍历每个检测 for detection in output[0, 0, :, :]: # 提取检测的置信度 confidence = detection[2] # 仅在检测置信度高于某个阈值时,绘制边界框,否则跳过 if confidence > .4: # 获取类的ID class_id = detection[1] # 将类的id 映射到类 class_name = class_names[int(class_id) - 1] color = COLORS[int(class_id)] # 获取边界框坐标 box_x = detection[3] * image_width box_y = detection[4] * image_height # 获取边界框的宽度和高度 box_width = detection[5] * image_width box_height = detection[6] * image_height # 在每个检测到的对象周围绘制一个矩形 cv.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2) # 将类名文本写在检测到的对象上 cv.putText(image, class_name, (int(box_x), int(box_y - 5)), cv.FONT_HERSHEY_SIMPLEX, 1, color, 2) return image1.4.3、启动
xxxxxxxxxxcd ~/transbot_ws/src/transbot_visual/detectionpython target_detection.py
点击图像框后,使用键盘【f】键切换人体姿态估计。
xxxxxxxxxxif action == ord('f'):state = not state # 功能切换